Artificial Intelligence can Erase Technical Debt
Claude Code and I rewrote a nine year old, complex Python project I maintain, in GoLang, in 5 Days

You would be wise to view my subtitled claim skeptically: Rewrote a nine-year-old software project in 5 days? Yeah. Right. The claim seems to play into a core fear at this moment, and it has the current generation of undergraduates feeling skeptical about careers in computing. “Nobody’s going to need to know how to code anymore”, I hear (you can jump to the end for my 2 cents on why I think that fear is not warranted). For those inclined to code, I salute you. The links to the old program, Augur1, and the new program, Aveloxis2, are in the footnotes.
The headline is unbelievable because “AI is amazing” or “AI is terrifying” are movie themes from decades ago, and present-day clickbait. Let’s start with some summary statistics. Augur has 259 open issues. The AI-Assisted rewrite eliminates more than 80% of them.

Folks who write software will quickly note that it may be the case that nobody’s found the bugs in Aveloxis yet. That’s fair3, and it gets me to what I think we might all learn from this experiment, aka “the important part,” and to a more sober reflection on the role AI is likely to play in software development and computing in the coming years.
These highlights will guide you toward takeaways you can use as you face a world with AI-assisted software:
Prompt Engineering is a curious phrase.
Experts on the problem are usually not experts on the solution.
We, as humans, remain terrible at describing what we want a system to do.
Prompt Engineering
In a short lifespan, the phrase “prompt engineering” already represents as many different “things” as love. Or so it feels some days. It’s a phrase alternately used to describe attempting to “jailbreak”, or trick web-based LLMs into answering questions they are not supposed to answer4, find relevant literature for scientists5, and, yes, to produce “source code.”6 This sample of three uses of prompt engineering all share one property: each describes building something small and simple enough that most of us can understand what “the thing” is, the “problem” it solves, and the relationship between the two. The articles I point you to in the footnotes each describe an iterative process between the AI (LLM) and the human, which is perhaps the origin of the word “engineering”.
AI is now capable of handling more than the small cases described over the past four years. Entire complex software systems are where engineering and AI authentically come into contact. In five days, from April 6 through 10th7, I recreated an entire, complex software system using a relatively new incarnation of AI: Claude Code8, which was conceived about a year ago9, and started being actively promoted around four months ago10. Aveloxis was published to GitHub on April 10th, and I’ve been stress-testing it and verifying new features over the weekend while also doing my job.
What do I mean, specifically, when I refer to Augur as a complex software system? Around 155 people have committed code to Augur over those nine years, and hundreds more contributed through the issues, comments on issues, and other work as part of the CHAOSS project, which I co-founded in 2017, shortly after Derek Howard and I started working on Augur. It became a substantial undertaking of open source software maintainership11, and yes, engineering12.
The Problem and the Solution
If creating Aveloxis was not an exercise in prompt engineering, then what was it? Have you ever experienced technology arriving around the exact moment you need it? And, you happen to understand the problem you are solving and its current software solution, with incredible depth? Me neither. Until now, and by accident.
Being the co-founder of a project on open-source software community health and sustainability, and the creator and one of the maintainers of widely used software in that space, is an unusual perspective, and, candidly, kind of a prerequisite for replicating this ridiculously fast success.
Most people don’t have the opportunity to work on one piece of software consistently for nine years (the solution) after co-founding a group focused on defining the metrics for defining what that software would measure. I understand the problem in depth. For nine years, I built and helped maintain a software solution used by many to accomplish the project’s goals.
What do I know about the problem space? Every single issue, wish, and complaint ever registered against Augur. And Augur is far from perfect. It was always sufficient, and more so than other solutions, for some people and organizations. I also know well what the CHAOSS project set out to accomplish. Kind of an intensely fun crucible that’s been part of my life for nearly a decade.
Humans are Not Good at Describing What we Want Software to do
Every software project you’ve ever observed, read about, participated in, or been run over by ran into difficulty because, to one degree or another, the folks who wanted it built and the folks building it communicated poorly. If you want to claim to be aware of a software project in which none of these issues occurred, we either share a rare experience, or you were not as much a part of that project as you think you were. In this exceedingly rare case, any communication problem between the folk who want it built and the folk who are building it is more of a mental health issue for me than a communication issue.
Walking Through The AI Engineering of Aveloxis
This word, “engineering,” can be thrown around too casually for what it implies. I’ve been writing code since I was 21, and I’ve been a computer science-oriented sociotechnical researcher, teacher, and professor for the better part of the past 25 years. People who train engineers generally incorporate science & math, problem-solving, and building things into their definition of engineering13.
What about copyright? Good question. First, as a copyright holder for Augur, I’m not leveraging anyone else’s copyrighted work. Second, since Augur and Aveloxis are both MIT licensed as open source projects, most people are reasonably free to do as they wish, as long as they give the original project and it’s copyright holders, if they exist, credit.
In some respects, certainly in hindsight, there are some good general practices you might be interested in if you want to take Claude Code or a similar tool for a spin. At a high level, Figure 2 is the structure I created from the beginning.

Keep “The rules” in your CLAUDE.md file. Mine opened like this:
Aveloxis is a Go replacement for the Python-based [Augur](https://github.com/chaoss/augur) open source community health data collection pipeline. It collects data from GitHub and GitLab APIs, parses git logs, stores everything in PostgreSQL with full Augur schema parity (108+ tables across two schemas), and includes features Augur lacks: staged collection for 400K+ repos, deterministic contributor IDs, dead repo sidelining, SBOM generation, OpenSSF Scorecard, vulnerability scanning, interactive visualizations, and a web GUI with OAuth. Complete parity and equality in collection of GitHub and GitLab data is a major goal, where possible. Use GitHub as the base. If equivalent GitLab data is unavailable, make sure it is documented in the README.md file and the docs/ folder. **CRITICAL** Tests must cover edge cases. **CRITICAL** Everything that errors should be logged.
And, as I iterated through each day, that document grew as a reflection of key decisions. That part is important because the AI doesn’t have the sort of recollection of your last discussion we might all hope for.
Session One
Knowing the architectural decisions that live within Augur, and what I did and did not think was smart in hindsight, combined with AI, let me eliminate a lot of technical debt and begin evaluating a working system by the end of the first day. That is kind of insane, and frankly, it was at the end of that session when something I started as one of those “I wonder what would happen if?” experiments suddenly felt realistic.

Key Design Decision on Day One: Ensure Repositories Are Individually Complete Almost Always
The staging pipeline design decision fixed, with one decision, one of the most frustrating aspects of operating a very large Augur instance (100,000+ repositories): Uncertainty about how complete data collection was at any given time for each repository. I had ways to get at it, but because we decided to collect data in parallel by data type, on many days we operated under the assumption that some of the data, like messages or pull request reviews, could be a month or more behind. The switch to parallel, per-repo collection in Aveloxis is a game-changer.
Augur: Parallel Collection / Aveloxis: Sequential per-repo Collection
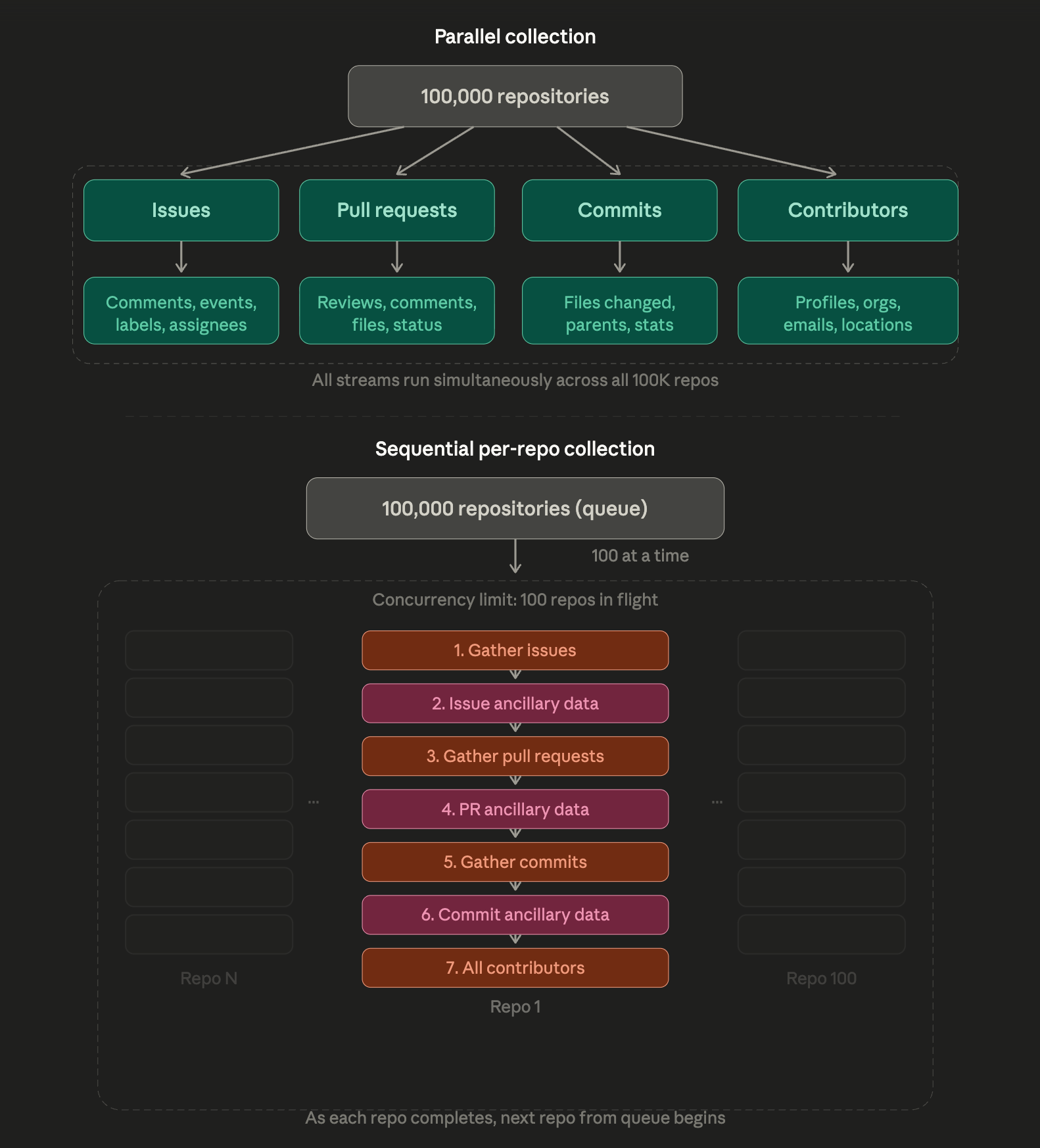
Sessions’s Two and Three
With a working foundation after one session, I immediately started testing Aveloxis. So, Day 2 started by addressing issues I knew would be critical, because after 9 years of collecting sometimes irregular API data and handling all those irregularities, I knew what to look for and ask for before I tested it.

Sessions Four and Five
Three days after setting out on this experiment, I started adding a few of the helpful monitoring and management tools that Augur’s users had long wished for. We didn’t get to building them because open-source software maintainers spend most of their time reviewing other people’s work and providing feedback. We fix clogged sinks and review plans for compliance with local ordinances, in a way.

Session 6: Breaking Everything that Ever Broke in Augur and Hardening Aveloxis Features
On Thursday and Friday evenings, I identified locking issues that were short-circuiting collection on large repositories with long histories, as well as issues with the contributor collection. Here’s where living with the solution used by many for nine years made it routine to identify where things were breaking in Aveloxis, and fix them before ever launching the project publicly.
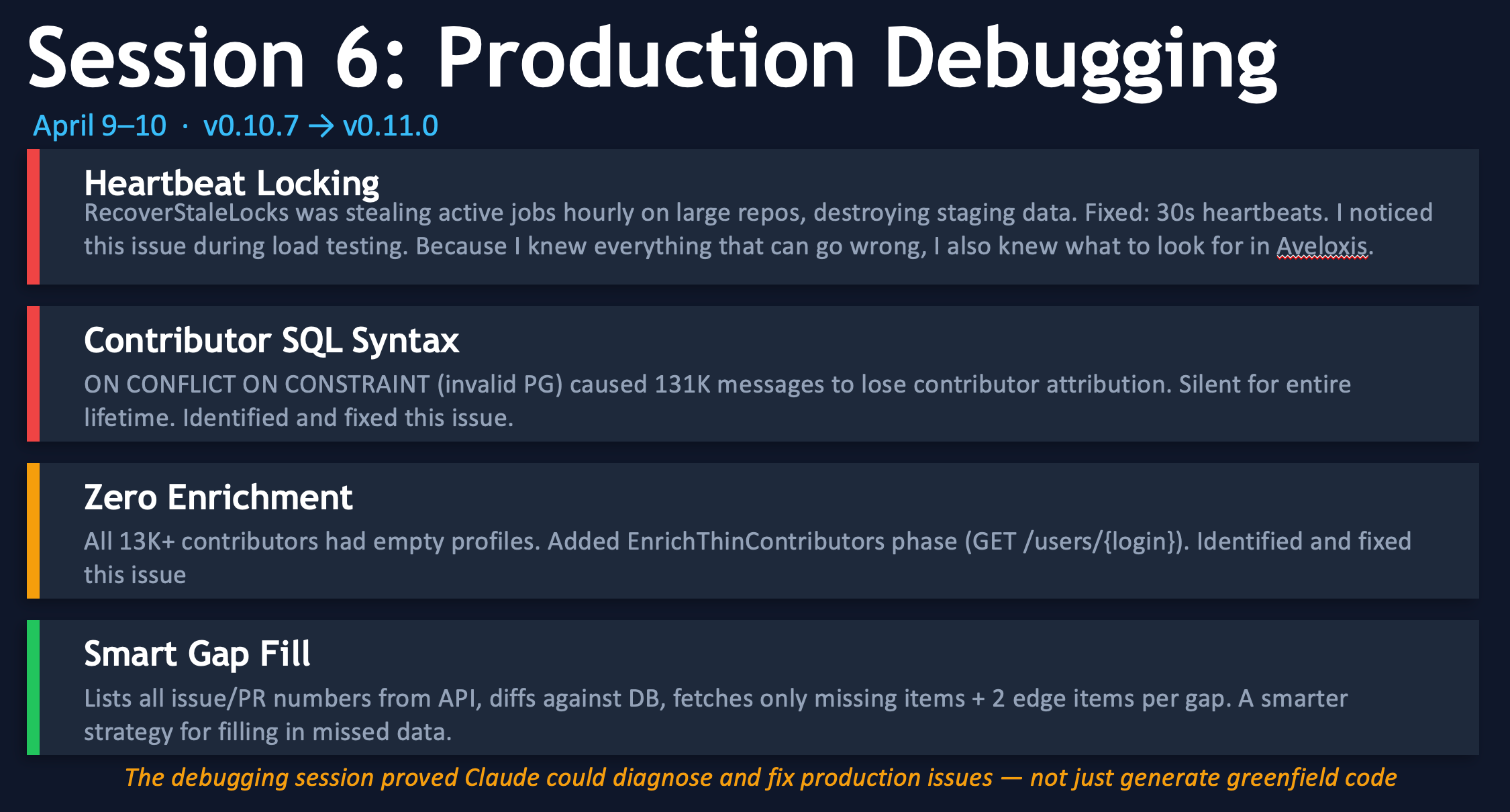
The Weekend: Which brings us to April 12th, or “Day 7.”
I spent a good deal of Saturday running Aveloxis on three different computers. One I used repeatedly to collect two repositories I know well to verify data was fully collected; another I used for a set of very large repositories, configured to do “Full Recollection” every 12 hours to see if it broke anything (it didn’t). Every 12 hours is prety aggressive and entirely unrealsistic if you’re collecting 100,000 or more repositories. Or even 10,000. The third computer I used was to fix the bugs identified by the first two. With Claude’s help, of course.
Every instruction I gave Claude included some version of this bounding text, which is helpful if you don’t want to burn through your tokens with poor decisions:
Prompt: I need you to implement the following features in Aveloxis, one at a time. For each feature:
1) Write comprehensive Go tests first,
2) Run `go test ./...` to confirm they fail,
3) Implement the feature across all necessary files,
4) Run tests again and iterate until all pass,
5) Move to the next feature.
Claude is NOT an Artificial Intelligence Like Those We Already Know
Thinking back to my earlier comments about “prompt engineering”, I think this makes the point even more clearly. I’m treating a coding machine like a toddler because it has the recall of a toddler. Claude code requires you to frequently remind it of these basic concepts. In this respect, I think more than others, it is clear that this is not an “artificial intelligence” so much as it is a systematic implementation of patterns using some kind of logical structure. This reminds me of the points Phil Agre made regarding the 1960’s, MIT-centered incarnation of “AI”14:
This is the essential problem of serial order: The existence of generalized schemata of action which determine the sequence of specific acts, acts which in themselves or in their associations seem to have no temporal valence. … Two things are new to the cognitive theorizing here: grammar as a principle of mental structure and the generalization of grammatical form to all action.
What I’m saying here is that Claude Code is not a large language model, or it is at least not only a large language model. There is a systematic way of interacting with it in which, once it recognizes YOUR pattern of problem-solving, it will constrain your actions in much the same way that grammar attempts to constrain our writing and speaking. Imperfectly, but deliberately.
Ensuring Aveloxis Connects to 8Knot, Augur’s Visualization Dashboard
The final work I did over the weekend, on Saturday night and Sunday morning, was to ensure that Aveloxis supported all the necessary connections so that an 8Knot dashboard could run alongside it, connect to it, and do what it does without needing to change. This was accomplished with six database views, a few other adjustments, and a small pull request into the 8 knot project. If you want to try the whole stack out with Aveloxis, we have it working in our fork of 8Knot.
Counterpoint: Artificial Intelligence Can Generate Technical Debt Faster than Humans
I’ll make a future post covering this notion in depth. My observation through conversations with friends in industry is that AI tools are being nearly required for every level of software engineer. I don’t think this can avoid privileging code outputs over understanding the problem the code is supposed to solve. AI Code is often verbose, and if you can’t tell the tool very explicitly how it’s supposed to work, your software may run … and have errors that are not caught for weeks, months, or years. Somebody’s going to have to fix all of that, which is why I think the future is bright for computer science majors.
Complete Comparisons of Augur and Aveloxis
These documents are provided for the very bored and devastatingly curious among those who have made it this far. The first one is a detailed analysis of how the open issues in Augur are mostly resolved in Aveloxis.
This next one is a feature comparison of Augur and Aveloxis.
You can reach me at outdoors@acm.org if you have any questions.
Now, I think I’ll enjoy the rest of my Sunday.

I would argue that after nine years, I’ve seen all the different ways open-source health data collection can break, and I’ve run Aveloxis through its paces with up to 1,000 repositories without issue. I’m currently running a 10,000 repository test.
True Story: I also submitted an NSF Grant Proposal on Wednesday, the 8th. Just in case they still exist next year.
I recommend Herb Simon’s “The Science of the Artificial” for a full coverage of the sort of engineering at the center of software and AI. tl;dr - It is the human negotiating with their environment through artificial (not of the natural world) systems.